為什麼要學爬蟲?
解鎖你的網路力-讓你輕鬆徜徉在網路海中,「截」你所需,「取」你所要

- Wendy Lai
- 1 min read

如果想要從網路上取得某個資訊,像是這個月各大書店暢銷書的價格比較,除了開啟好幾個分頁,一本一本比價外,有沒有什麼方式可以一鍵完成呢?
像這樣重複性高,數量眾多,又與網頁相關的問題,就不得不提到「爬蟲」這件事
什麼是爬蟲
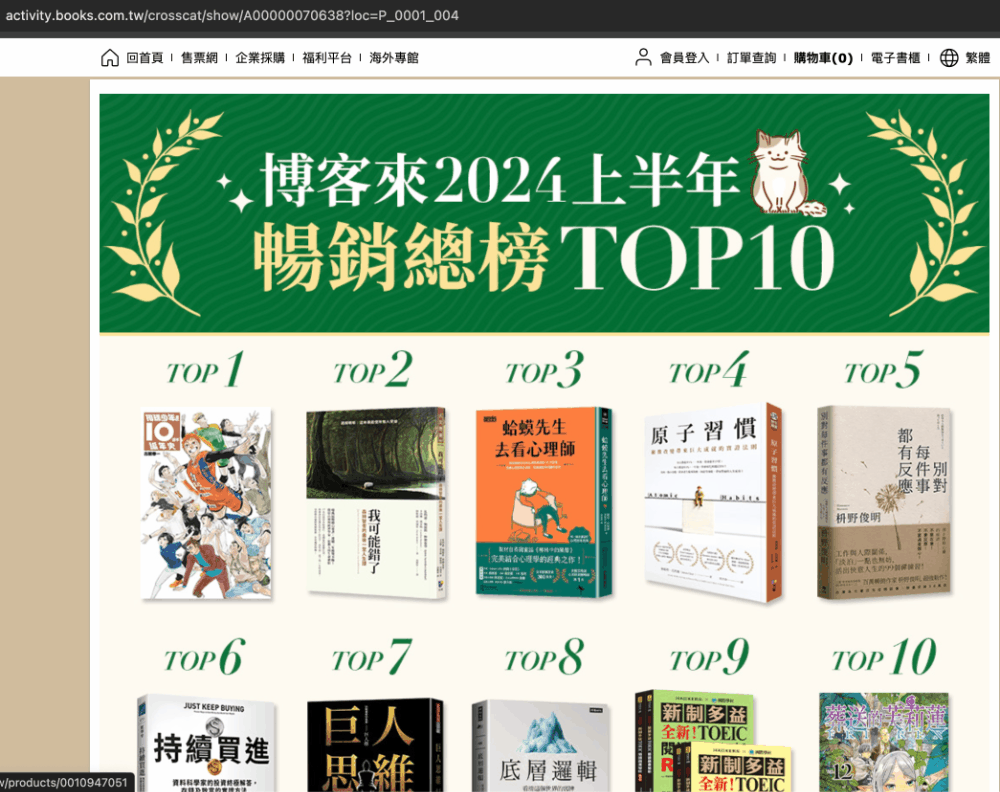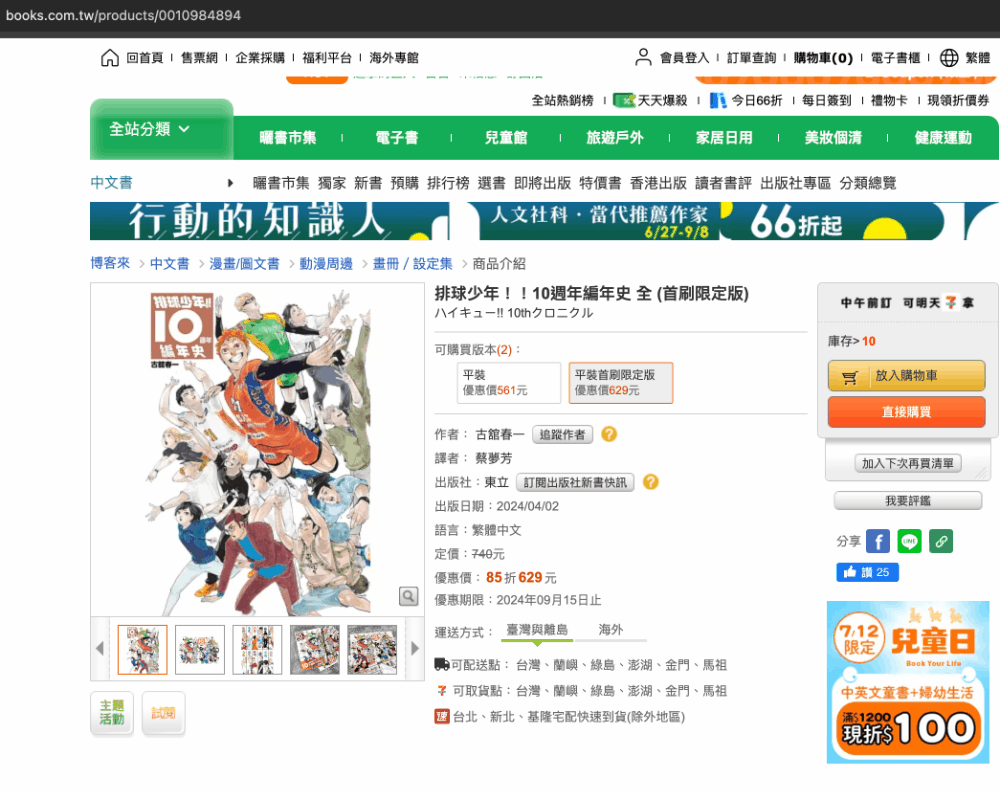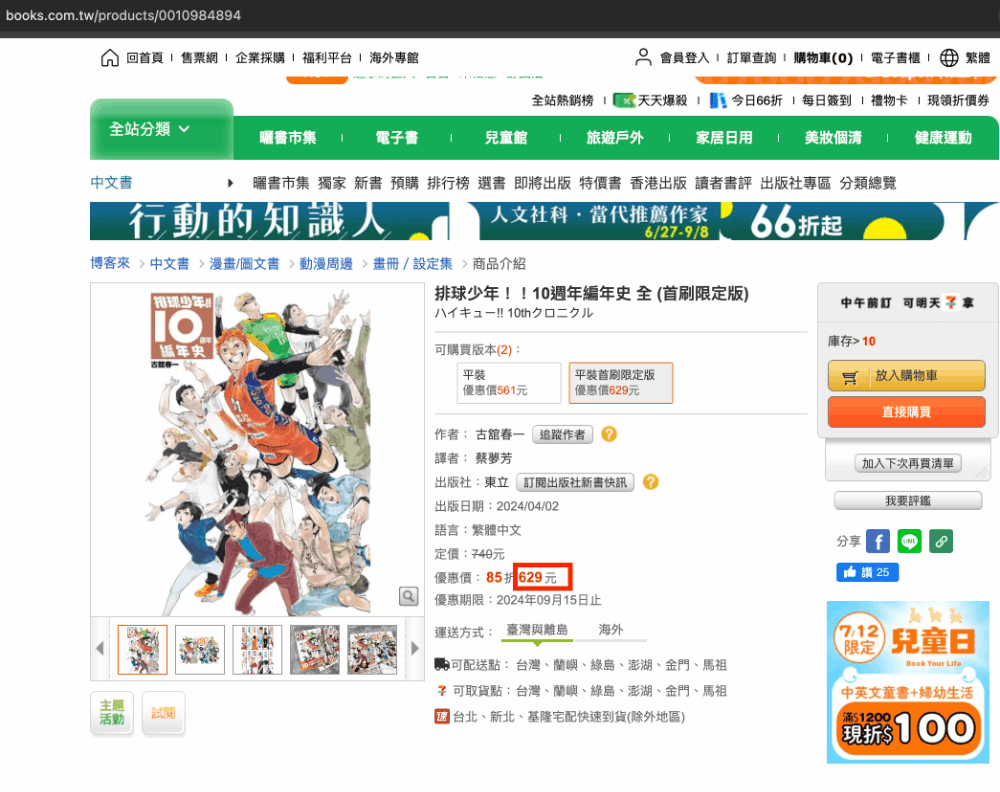
簡單來說就是透過程式將網路伺服器回傳給瀏覽器的資料擷取下來,從中取得使用者有興趣的部分 以這個例子來說就是某本書的在某個電商平台上的價錢
要怎麼實作呢?
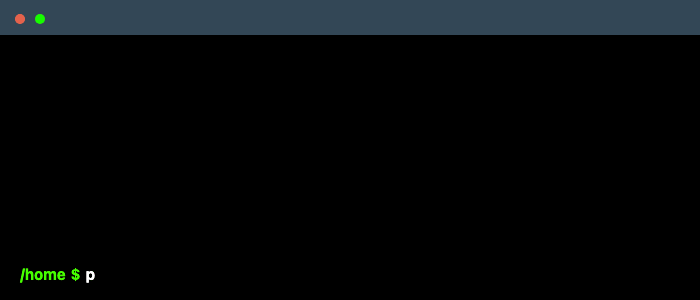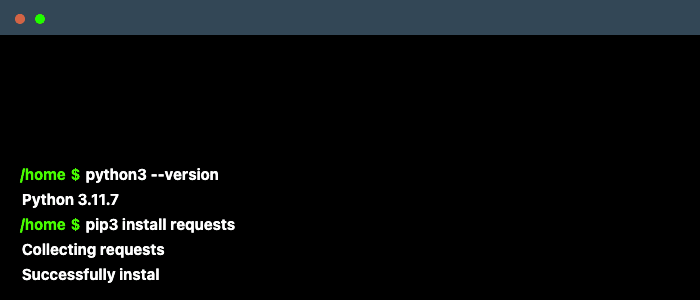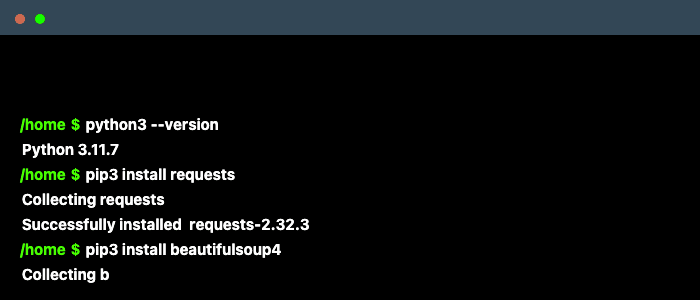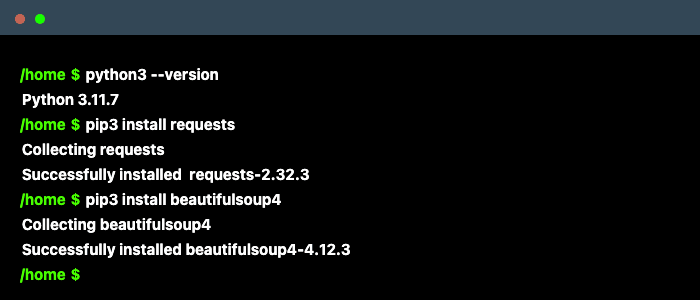
- 安裝Python 和 Python package (以Python3為例)
- Python 官網下載
- requests
- 最常使用到的get這個function
- 可以從r.text得到我們想要的資訊(針對package的內容以HTTP header為基準做初步的解碼)
import requests r = requests.get('https://www.books.com.tw/') r.text - beautifulsoup
- 解析HTML結構,將取回的網頁HTML結構,透過其提供的方法(Method),能夠輕鬆的搜尋及擷取網頁上所需的資料
- HTML結構和網站組成細節可參考網站是怎麼構成的?
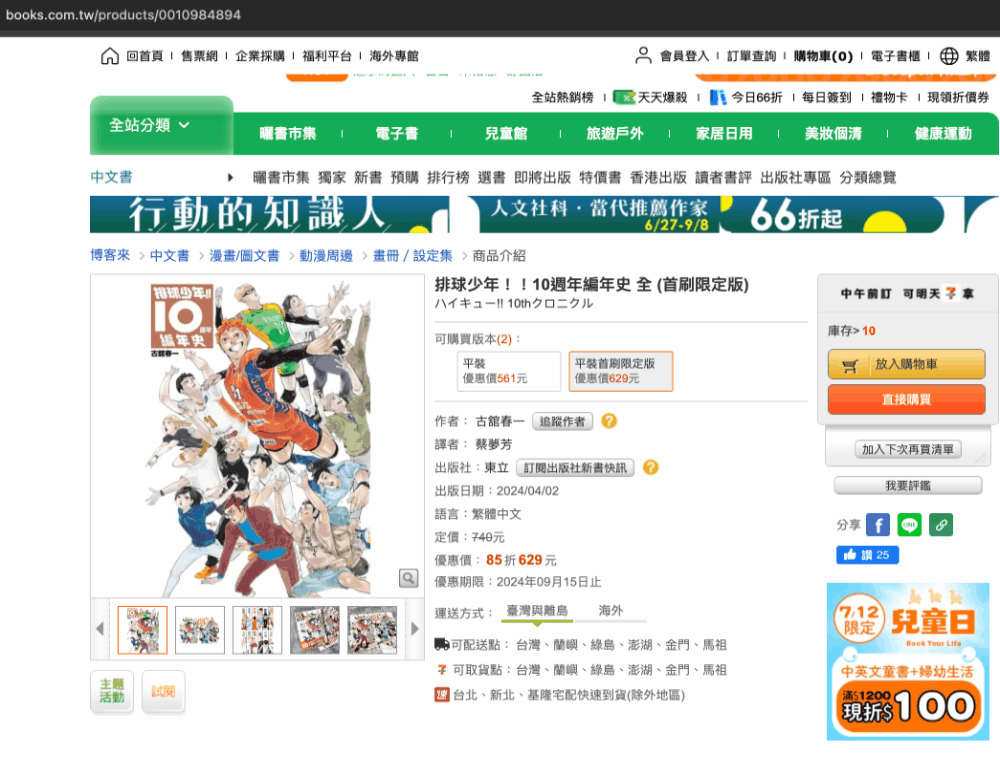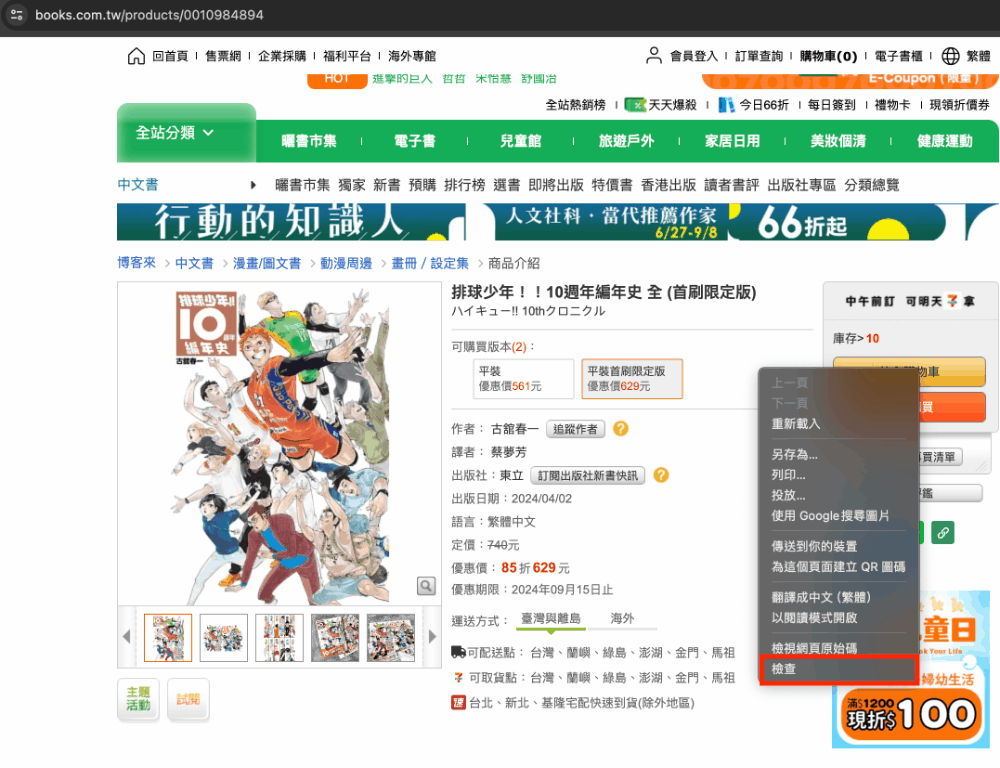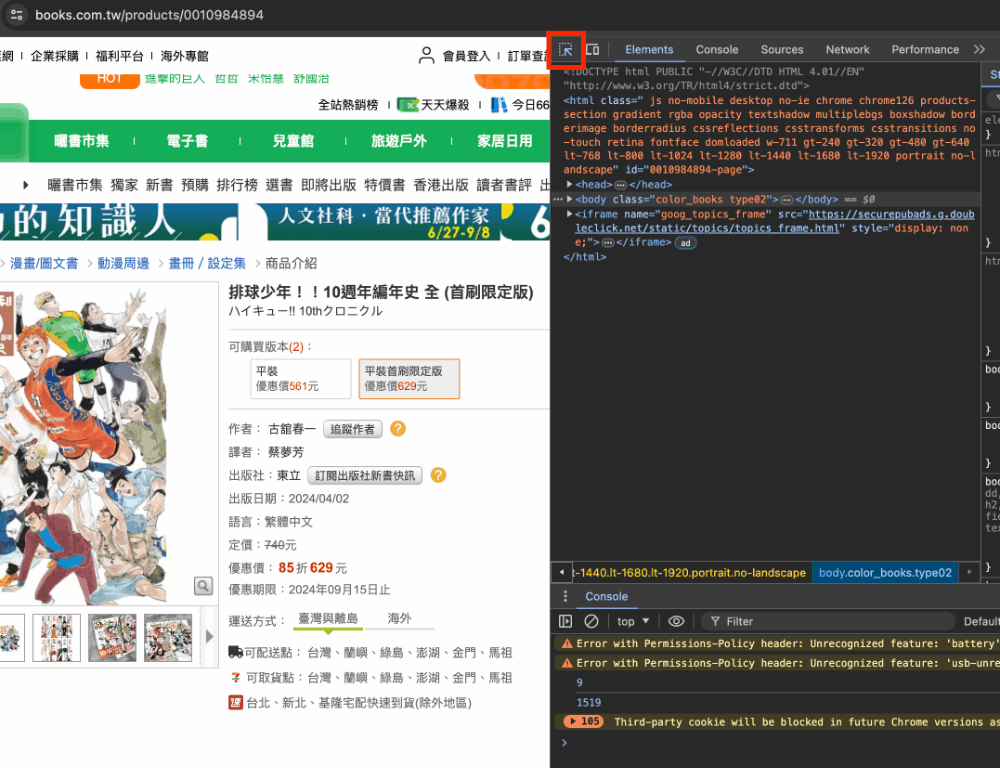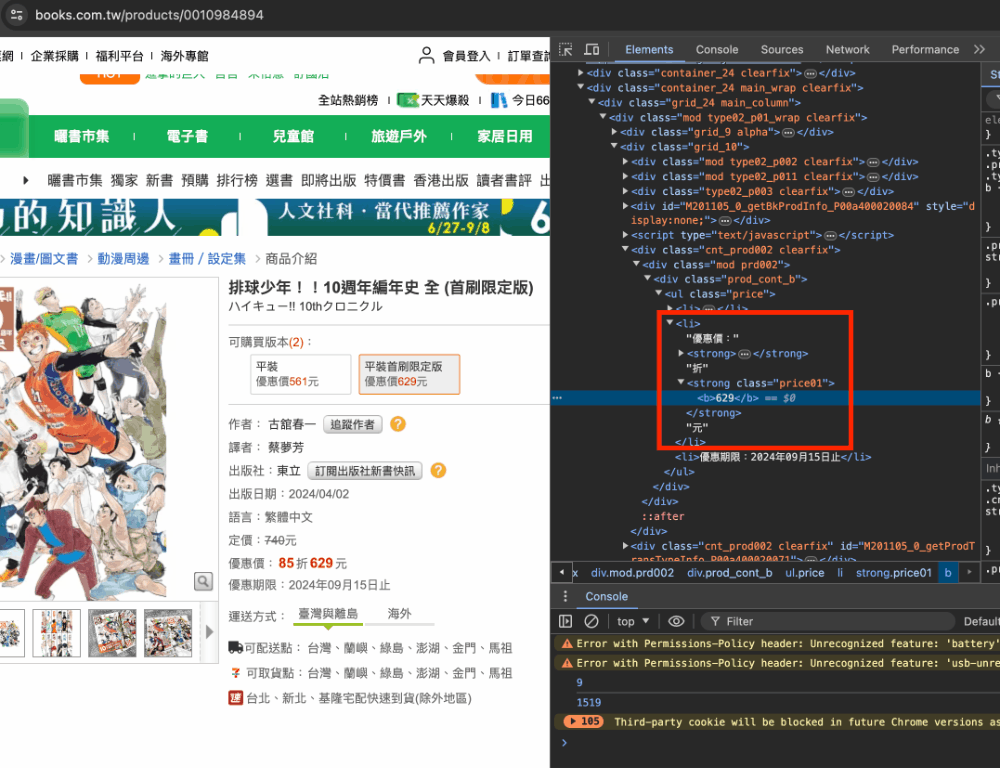
- 分析網頁架構 (以chrome browser為例)
- 進入網頁後按右鍵或F12可看在檢查這個選項
- 點選左上角的按鈕後
- 找到想要書籍的圖片點下去後
- 就可以對應到相對的HTML內容
- 使用上述安裝的packages
import requests
from bs4 import BeautifulSoup
r = requests.get('https://www.books.com.tw/products/0010984894')
soup = BeautifulSoup(r.content, "html.parser")
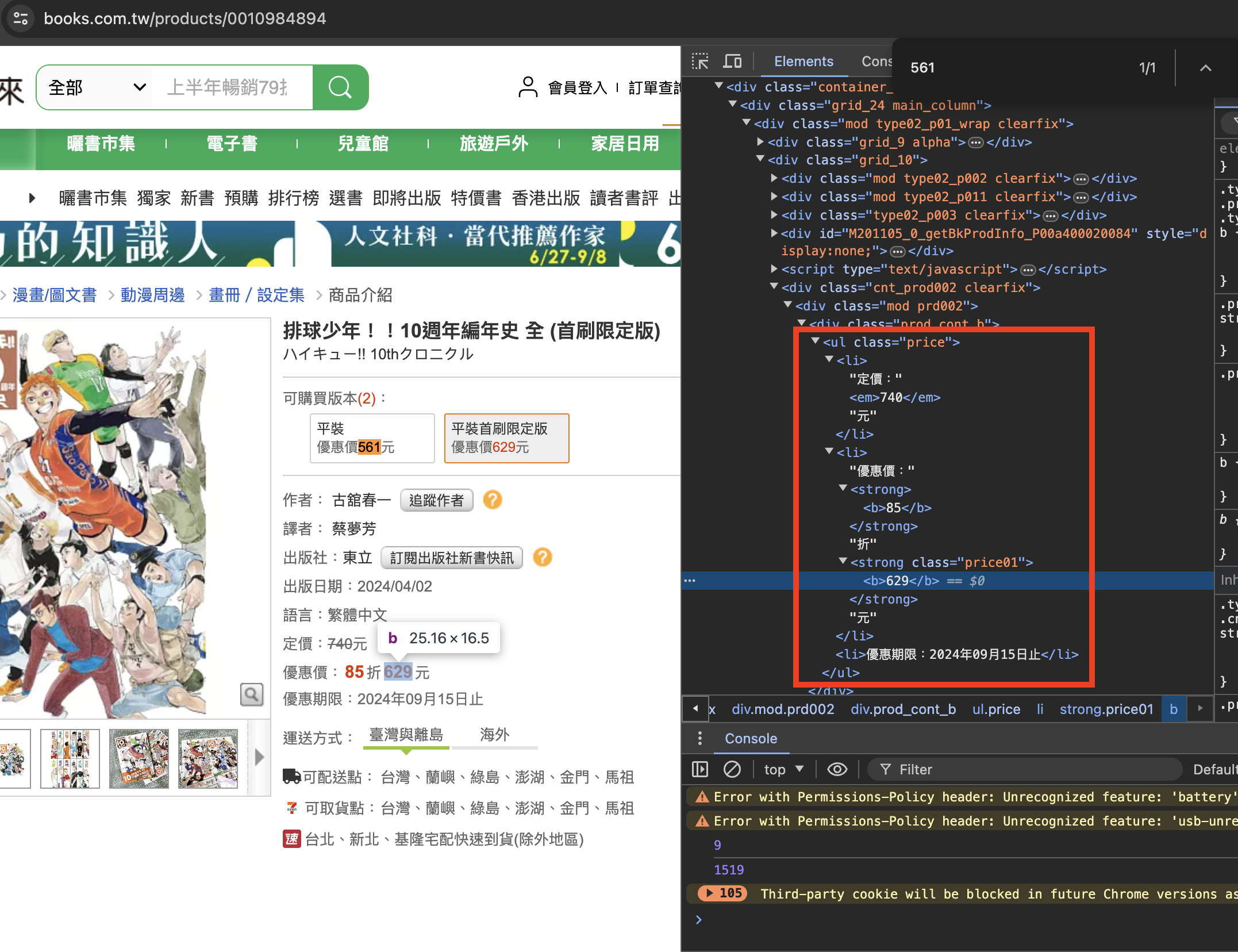
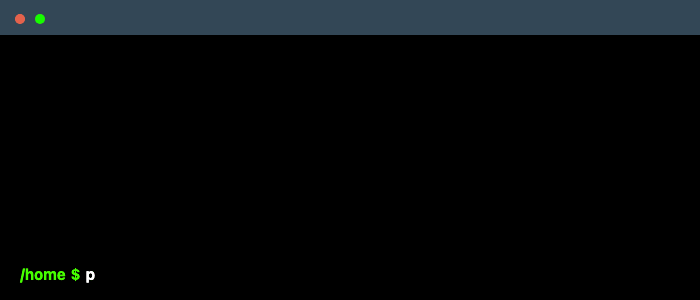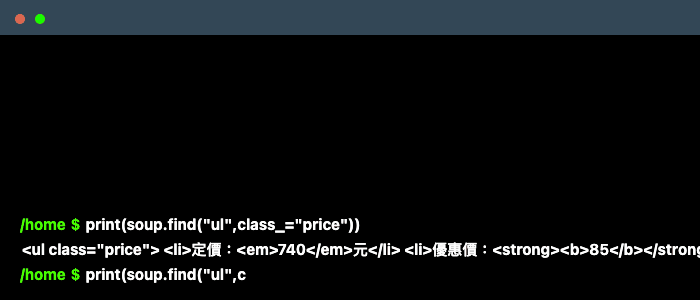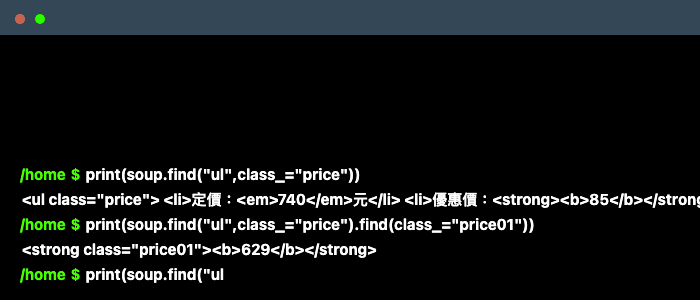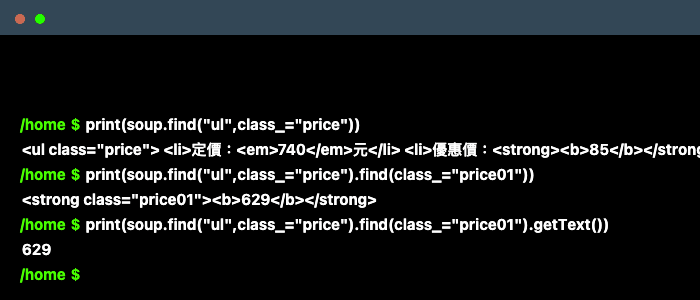
price = soup.find("ul",class_="price").find(class_="price01").getText()
將BeautifulSoup得到的資料加以拆解
- soup.find(‘標籤名稱’, ‘屬性’=‘數值’)
- 我們要得到的金額是包含在<ul> 這個標籤下class屬性是“price”的這個大框架下
- 亦可用 ‘attrs’
soup.find("ul", attrs={"class" : "price"}) - 再進一步往下去定位到“price01”這個class
- 我們要得到的金額是包含在<ul> 這個標籤下class屬性是“price”的這個大框架下
- soup.getText()
- 取得最內層的數值,就是我們想要的資訊
其他常用的Method
- soup.find_all(‘標籤名稱’)
- 擷取文檔內所有同標籤的內容
- tag.get(‘屬性’)
- 取得標籤中某個屬性的數值
從CSS類別下手
soup.select(‘CSS的語法選擇’)
- 在CSS中, . 代表class這個屬性, #代表id這個屬性, ‘>’ 則意味著繼續往下一層搜尋的意思
- soup.select_one(), 指的是符合篩選條件的第一個元件
- 原本的寫法亦可改寫成這樣
soup.select_one('ul.price > li > strong.price01').getText()
To Be Continued …
乍看之下,我們一開始提出的問題好像已經解決了 但我們要怎麼從電商平台的首頁找到暢銷榜? 和要怎麼從暢銷版連結到每個排名的書籍呢?
這就不得不進一步提到selenium 和webdriver 這兩個工具 請繼續看下去